Appearance
01 笔记
AI 的出现会打破现有的环境,古法编程。
AI 就是模拟人 → CNN,RNN → Attention 算法 → LLM 的核心
科学家们又是咋想出来弄出这些人工智能的东西呢?仿生!
解剖动物的脑细胞 → 生物学 → 神经元(神经细胞)结构
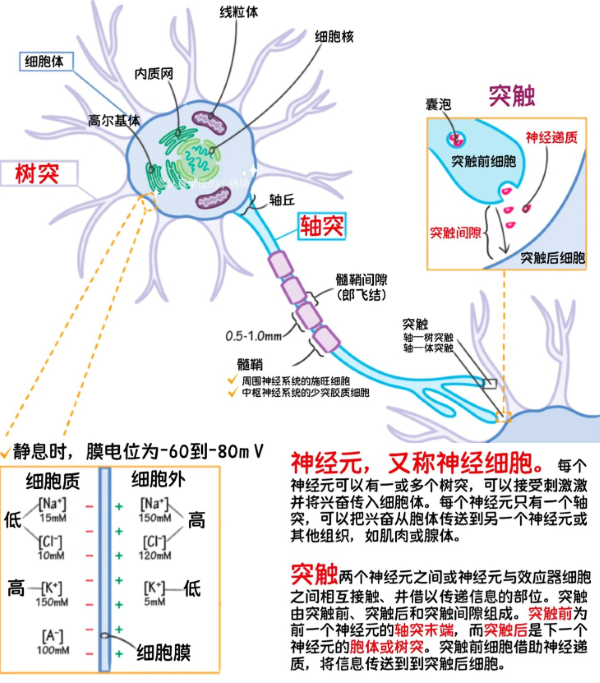
那么,我们的细胞是怎么把细胞数据传递到下一个细胞上去的呢?
由突触后细胞和突触前细胞传递神经递质,神经递质即数据(信号)。它接收到了数据信号之后,调节了膜电位,调节电位差之后产生了微电流,通过这个微电流把数据再传递到其他细胞。
我们发现,一个神经细胞要不要把上一个神经细胞的数据,通过神经这个突触传递到下一个细胞去?那这个时候是不是需要有一定的阈值?这个阈值就是要达到我们的这个电位差,比如说达到现在的-80毫伏,拉高电平之后,就可以把数据传出去。于是有没有感觉到这些神经细胞的小颗粒有点像输入数据和权重之间的关系。
比如说:y = kx + b ,这个线性函数。
可不可以在输出给y的时候做一个判断,当等式大于 0 的场合才赋值给 y。这里用一个一维的线性函数就可以模拟我们神经元的一个传递过程。
此时把函数换成 y = wx + b,比如此时把权重w调成2,偏置b调成-2,假如上一个神经元传过来的x是1,请问y有值吗?是不是没有值,所以此神经细胞就不激活,即你的数据传到我这,我这个神经细胞就不响应。
我们再来看一个复杂一点的:
y1 = w1 * x1 + w2 * x2 + w3 * x3
假设:
xi 都是上一个神经细胞传递过来的小突触,
wi 有各自的权重值比如 0.11, 0.12, 0.21,
我对 y1 做一个阈值,比如说 y1 当大于 0.1 就把这个神经细胞的神经元生成一个小突触,然后往下一个神经细胞去传递。
这样做是不是就是用方程去模拟神经元细胞?然后通过某个算法把这里的权重调成正确的权重。
比如一个刚出生的小孩,当他用眼睛观察世界的时候感受到了光,于是大人告诉他这东西叫光,此时他就把这个对应的权重调高(如0.1→0.2),这样他的神经细胞就记住了。下次他看到光的时候,就是眼睛传来一个参数,然后加起来得到一个 y1 ,当 y1 大于阈值的时候,大脑告诉他这叫光。
发现了吗?就是调节权重(w1,w2,w3),这就是机器学习。
总结就是:
人类研究动物神经细胞时,发现神经细胞在接收到神经递质时,会激活内部膜电位,当电位差达到一定阈值时,它会将信号传递到下一个与之关联的神经细胞。
→ 那么科学家就使用数学公式对其建模:
y = w1 * x1 + w2 * x2 + w3 * x3 ( wi 就是模拟调节点位差,xi 就是模拟神经递质信号)
→ wi 为权重,xi 为 token
神经细胞可以关联,我可不可以传递多个:
y = w1 * x1 + w2 * x2 + w3 * x3
y = w1 * x1 + w2 * x2 + w3 * x3
y = w1 * x1 + w2 * x2 + w3 * x3
于是,形成了神经网络。
这种公式,可以写成矩阵 → 线性代数(映射 坐标变换 → 在相同坐标轴伸缩、变换,在不同坐标轴升维、降维) → 数据表示方法(矩阵)
向量:有大小 有方向
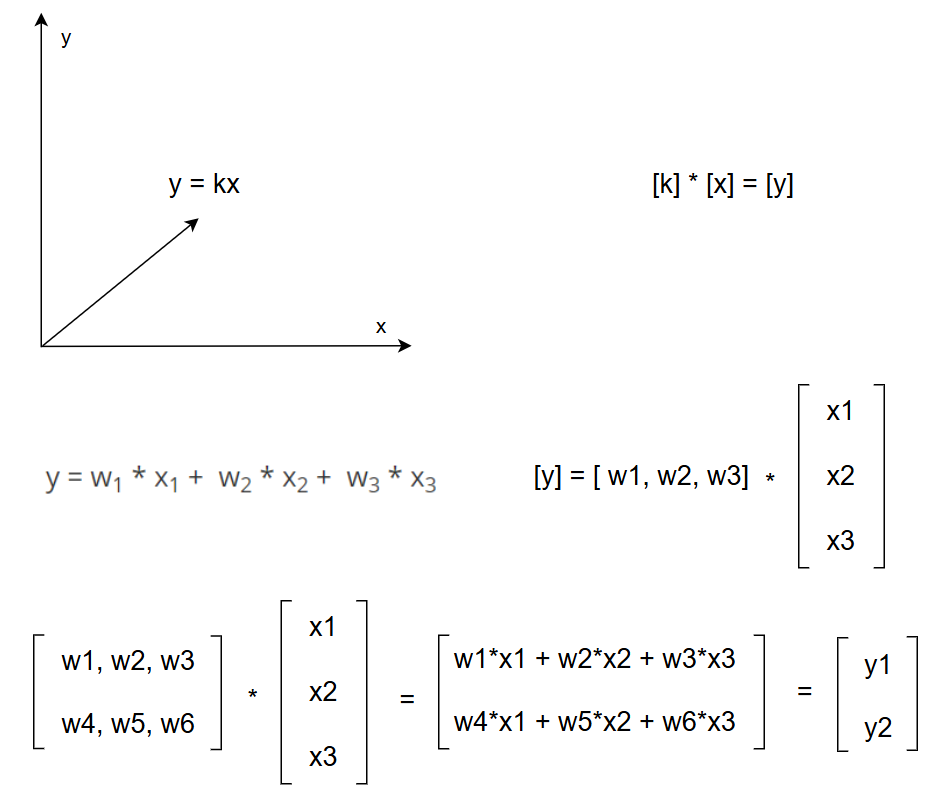
2行3列(1※3)点积 3行1列(3 ※1) = 1行1列(1 ※1) → 得到的是 (左行※右列)
T:转置,行变列 列变行。
向量的维度:列数
向量的维度压缩: (1※3) ※ (3※2) ==> (1※2) → 降维
向量的维度扩张: (1※3) ※ (3※7) ==> (1※7) → 升维
于是,我们这样就可以用矩阵来建模神经网络。
那么,人类理解的东西是怎么到向量维度上去的呢?
我们就看这四个字:《我爱中国》

AI是怎么生成出来的呢?
第一步分词:我,爱,中,国
第二步把文字变为数据,文字怎么变为数据呢?字典表(映射)
| ID | 文字编码 | 维度1-词性 | 维度2-情绪 | 维度3-场景 |
|---|---|---|---|---|
| 1 | 我 | |||
| 2 | 爱 | |||
| 3 | 中 | |||
| 4 | 国 |
由于向量的维度是列数,所以这里就有一个4※3的矩阵。
该矩阵的每一行的数据表示:每一个字的元数据信息
该矩阵的每一列的数据表示:每一个字的维度信息
这里就要引入attention算法了,即自注意力机制。此时,我们让 ai 帮助我们学习 attention 算法:
提示词:
【角色】
你是一个大模型专家,精通 attention 算法。
【需求】
我是一个大模型的学生,需要学习 attention 算法。
【要求】
1.必须保证 attention 算法的每一个计算过程的矩阵清晰明了
2.样例使用 4*3 的矩阵
3.字典表 token 为:我爱中国,分词为 4 个单字
4.展示输入我爱两个字,模型输出中国的样例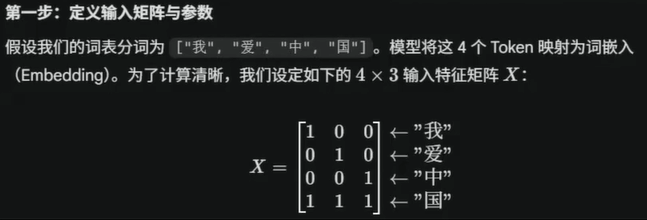
这就是上面提到的的 4*3 的矩阵

这里出现了 3 个矩阵:
Wq 矩阵:从三个维度压缩的数据中提取出独属于Q的数据
Wk 矩阵:从三个维度压缩的数据中提取出独属于K的数据
Wv 矩阵从三个维度压缩的数据中提取出独属于V的数据
I 是方阵,单位矩阵
→ 一个三维的词表,根本不可能保存那么多个的数据。RNN的那个算法就是用两个两个矩阵保存所有了所有的上下文数据,那可能吗?肯定是不可能啊,一到后面就梯度爆炸了,算到后面前面就忘了。因为你的脑细胞就那么大,你的杯子容量就那么大 你如10ml,你要硬往里放100ml,肯定不行啊。
→ 实际的此表的维度会非常大,通常:4096 维(列),甚至更高,所以实际在运算过程中,不是每一个维(列)单独表述一个数据信息(例如:三个维度都表示词性这个数据信息),通常是在训练时,多个列自己学习存储了多个信息。
→ 那么,行有多少个呢?token有多少个,行就有多少个。中文,英文,俄文等
→ 一个大模型能够支持这么多的语言,那这个行行数就token数大概有多少这个字典表,那至少都是几十万。 → 所以还觉得这个大模型支持越多语言它就越好吗?它支持越多的语言,它那个token,它的字典表就越大。这个表越大了,你输入的数据越多,然后这里面拆出来的词就越多,拆出来的词越多,来这个行数就越多,而且维度还有4096维(即4096列)。你的token如果输入了比如说一个代码,代码里边你输入进去一个public class,然后一个main函数里边就有多少行了。那么多行那么多列进去,就这么去计算,然后再拿wqkv计算过来,然后再拿b,然后再算soft max输入的是fnn里边升维。好一升为升到一万多维一本上,这个是四倍。然后一万多维。一万多维再弄完,弄完了之后再降维,然后再输入到第第二个第二层,第二层又来一次。。。你们知道计算量多大吗?几十亿次的运算。所以你们不要觉得它贵,学了底层原理之后,就会知道它贵是正常的,用电的。
Attention 机制的核心:
Query 表示的意思是:我是谁?我该跟谁连接?
Key 表示的意思是:我长啥样?我属于什么?
Value表示的意思是:我携带了哪些信息
| Q | K | V | |
|---|---|---|---|
| 我 | 名词,主语 | xxx | |
| 爱 | 动词,谓语 | 我属于动词,我可以表示情感 | |
| 中 | 名词,动词 | 我属于名词,我可以表示方位,我还可以表示国家名称 | |
| 国 | 名词 | 我属于名词,我可以表示国家,我常跟国家的信息连接在一起 |
QKV矩阵的形状:token的维度大小
→输入矩阵(我爱),所以是一个 2※3的矩阵。那么要乘以的QKV矩阵是什么样呢?是不是3※3,可不可以是3※4?不可以,因为要是4的话就升维了,我们现在是要提取数据,升维干什么,所以是3※3。